Data Availability Sampling: From Basics to Open Problems
Aug 25, 2022 | joachimneu
Introduction
A core responsibility of any layer-1 blockchain is to guarantee data availability. This guarantee is essential for clients to be able to interpret the layer-1 blockchain itself, and also as a foundation for higher-layer applications like rollups. For this purpose, an oft-discussed technique is random sampling for data availability verification, as popularized by a paper by Mustafa Al-Bassam, Alberto Sonnino, and Vitalik Buterin in 2018. This technology is at the core of the Celestia blockchain, and proposed for inclusion in proof-of-stake (PoS) Ethereum with “Danksharding.”
The purpose of this blog post is to explain the basics of data availability sampling (DAS), the model upon which it rests, and challenges and open problems when it comes to implementing the technique in practice. We hope that this post can “pill” researchers, attract them to the problem, and spur new ideas towards solving some of the outstanding challenges (cf. this recent Request for Proposals of the Ethereum Foundation).
The Problem
Somebody (such as a layer-1 block proposer or layer-2 sequencer) has produced a block of data. They claim to have made it “available” to the “public.” Your goal is to check the availability claim, i.e., would you actually be able to obtain the data if you needed to?
Availability of data is crucial. Optimistic fraud-proof-based systems, like Optimism, require data availability for verification, and even validity-proof-based systems, like StarkNet or Aztec, require data availability to ensure liveness (e.g., to prove asset ownership for a rollup’s escape hatch or forced transaction inclusion mechanism).
For the problem formulation so far, there is an easy “naive” testing procedure, which earlier systems like Bitcoin implicitly adopt: just try to download the entire block of data. If you succeed, you know it is available; if you do not succeed, you consider it unavailable. Now, however, we want to test for data availability without downloading too much data ourselves, e.g., because the data is larger than we can handle, or because it seems wasteful to spend a lot of bandwidth on data we aren’t actually interested in, “only” to verify its availability. At this point we need a model to clarify what it “means” to download or withhold only “part of the data.”
The Model
A common approach in computer science is to first describe a new technique in a model that has rather generous facilities; and to subsequently explain how that model can be realized. We take a similar approach with DAS, except, as we will see, interesting open R&D problems pop up when we attempt to instantiate the model.
In our model, there is a bulletin board in a dark room (see comic below). First, the block producer enters the room and gets the opportunity to write some information on the bulletin board. As the block producer exits, it can give you, the validator, a tiny piece of information (of size that does not scale linearly with the original data). You enter the room with a flashlight that has a very narrow light beam and is low on battery, so you can only read the writing on very few distinct locations of the bulletin board. Your goal is to convince yourself that indeed the block producer has left enough information on the bulletin board so that if you were to turn on the light and read the complete bulletin board, you would be able to recover the file.
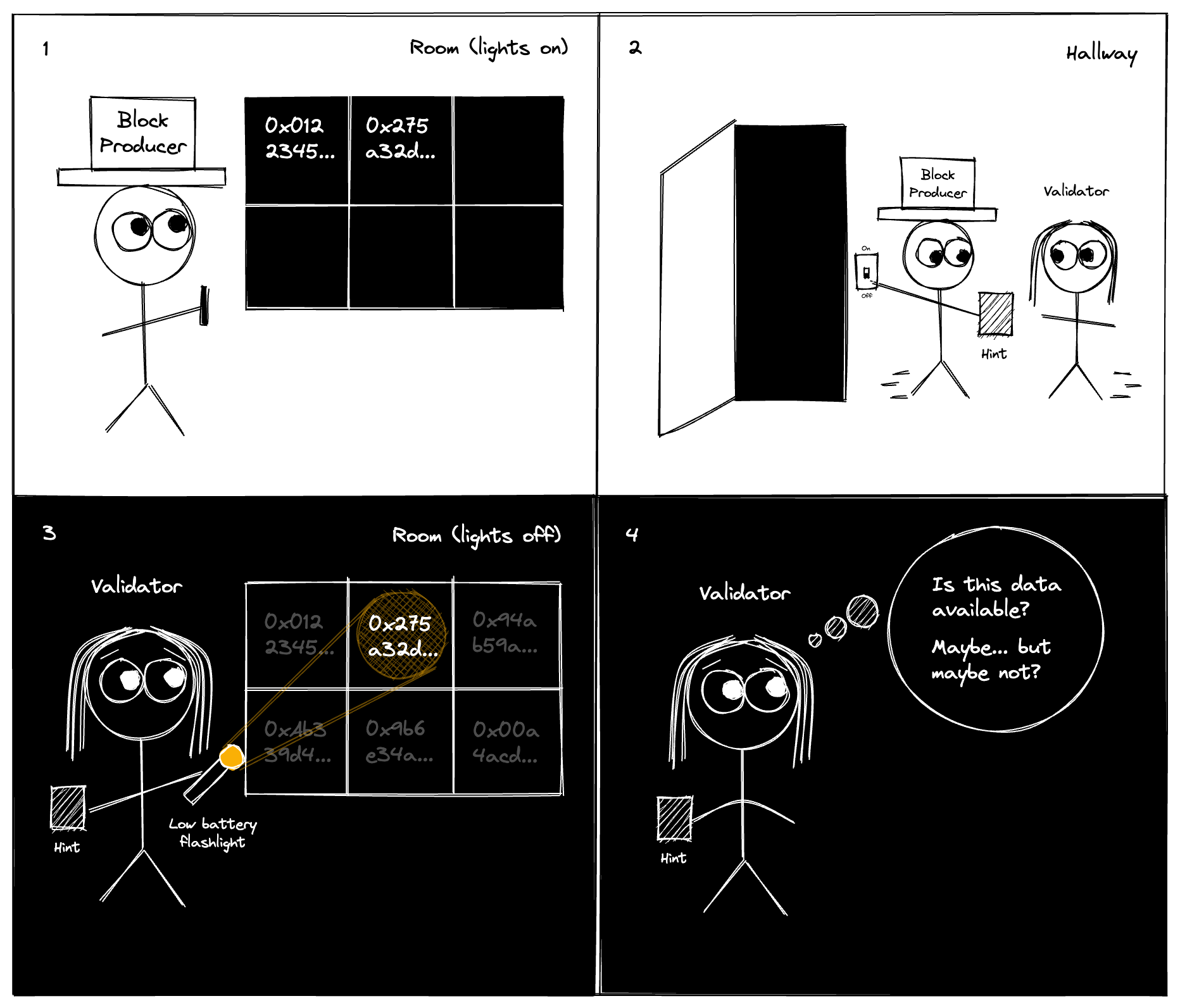
At first, this seems tricky: We can ask the block producer to write down the complete file on the bulletin board. Now consider two possibilities: Either the producer behaves honestly and writes down the complete file, or the producer misbehaves and leaves out some tiny chunk of the information, making the file as a whole unavailable. By inspecting the bulletin board at only a few locations, you cannot distinguish these two scenarios reliably—thus, you cannot check for data availability reliably. We need a new approach!
The (Theoretical) Solution
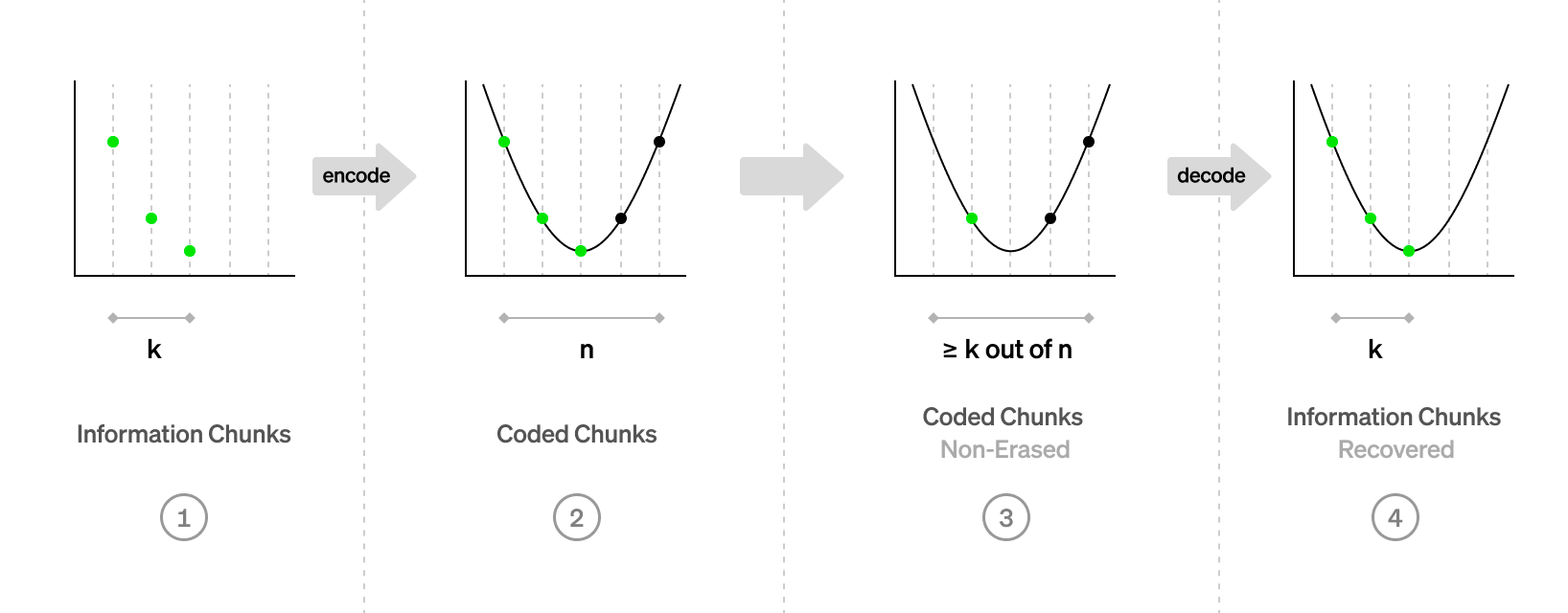
This is where erasure correcting Reed-Solomon codes come into play. Let’s take a brief detour to recap those. On a high level, an erasure correcting code works like this: A vector of
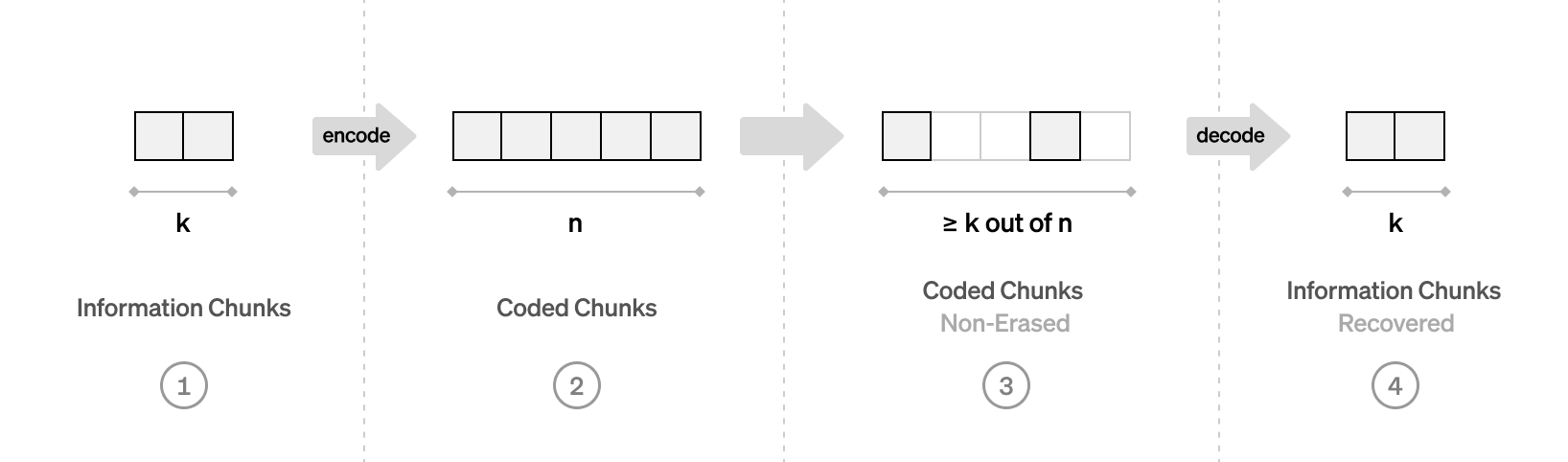
If the code is maximum distance separable (MDS), then the original

This is because a line can be described as a polynomial of degree 1 with two coefficients:
Reed-Solomon codes are built from this insight. For encoding, we start with the
Going back to our data availability problem: Instead of asking the block producer to write down the raw file on the bulletin board, we now ask it to cut the file in
But now these two scenarios, a bulletin board that is fully written, and a bulletin board that is half empty, are easily distinguishable: You inspect the bulletin board at a small number
The (Practical) Challenges
This is beautifully simple—within the given “bulletin board in a dark room” model. Let’s think about the model: What do the components represent? Can we realize them in a real computer system, and how?
In fact, to help spot the gaps between theory and practice, we have explained the problem and solution using that “strange” “bulletin board in a dark room” model, with metaphors that bear little resemblance to the real computational system. This was to encourage you to reflect about how aspects of the real and model world correspond, and how they might (not) be realized. If you are left with pieces of the model that you haven’t been able to translate into a computer/network/protocol equivalent, you know there is something left to be done—which might be either gaps in your understanding, or open research problems! ;)
Here is a non-exhaustive collection of challenges, for some of which the community has found reasonable answers over the years, while others are still open research problems.
Challenge A: How to ensure that the chunks on the bulletin board were actually written by the proposer? Think about alterations of the sampled chunks as they transit in whatever form on the network to the sampling node. This is where the small piece of information comes in that the block producer can pass to the sampling nodes as the producer leaves and the sampling node enters the dark room. In practice, this is realized as a binding vector commitment (think Merkle tree) to the original content written to the bulletin board, and it is shared for instance as part of the block header. Given the commitment, the block producer can then leave a proof with each coded chunk on the bulletin board to show that indeed the chunk was written by the block producer. The chunks cannot be altered by a third party on transit, as the commitment scheme does not allow to forge a valid proof for a modified chunk. Note that this by itself does not preclude that the block producer writes invalid/inconsistent chunks on the bulletin board, which we address next.
Challenge B: Enforce that the block producer erasure-encodes properly. We have assumed in the above scheme that the block producer encodes the information chunks correctly, so that the guarantees of the erasure-code hold, and that consequently from enough coded chunks it is actually possible to recover the information chunks. In other words, all the block producer can do is withhold chunks, but not confuse us with invalid chunks. In practice, there are three commonly discussed approaches to rule out invalid encoding:
- Fraud proofs. This approach relies on the fact that some sampling nodes are beefy enough to sample so many chunks that they can spot inconsistencies in the encoding of chunks and issue invalid encoding fraud proofs to mark the file in question as unavailable. Works in this line aim to minimize the number of chunks a node has to inspect (and forward as part of the fraud proof) to detect fraud (cf. the original Al-Bassam/Sonnino/Buterin paper uses 2D Reed-Solomon codes for this reason).
- Polynomial commitments. This approach uses KZG polynomial commitments as the binding vector commitment included in the block header to address challenge A. The polynomial commitment allows verifying Reed-Solomon coded chunks directly, based on a commitment to the uncoded information chunks, and thus leaves no room for invalid encoding. Think of it as: vector commitment and Reed-Solomon encoding are inseparable in polynomial commitments.
- Validity proofs. A cryptographic proof system could be used to prove correct erasure-encoding of the vector-commitment-committed coded chunks. This approach is a good pedagogical “mental model”, and generic with respect to the erasure code employed, but likely impractically inefficient for quite some time.
Challenge C: “What” and “where” is the bulletin board? How does the proposer “write” to it? Before we get to “what” and “where” the bulletin board “is”, how the proposer “writes” to it, and how the verifier “reads”/”samples” from it, let’s review well-known shortcomings of two basic peer-to-peer networking primitives:
- Low-degree flooding-based publish-subscribe gossip networks such as GossipSub, where communication is organized into different “broadcast groups” (“topics”) that participants can join (“subscribe”) and send messages (“publish”) to:
- Are not secure under arbitrary (“Byzantine”) adversarial behavior (e.g., eclipse attacks, Sybil attacks, attacks on peer discovery)
- Common variants do not even provide a Sybil resistance mechanism
- Privacy of a participant’s group membership from other participants is typically not guaranteed (in fact, group membership is typically communicated to peers in order to avoid them forwarding network traffic of unwanted topics)
- Communication tends to become unreliable if there is a large number of topics each with few subscribers (because the sub-graph of nodes subscribed to a particular topic might no longer be connected so that flooding might fail)
- Distributed hash tables (DHTs) such as Kademlia, where each participant stores a portion of the overall data stored in the hash table, and participants can quickly determine short paths to a peer that stores a particular piece of information:
- Are also not Byzantine fault tolerant (e.g., inappropriate routing of honest participants’ requests, attacks on network formation/maintenance)
- In fact, DHTs fare considerably worse in resilience to adversarial behavior than gossip protocols: Gossip protocols “only” require that the subgraph formed by honest nodes (and edges between honest nodes) is connected, so that information can reach from any honest node to all honest nodes. In DHTs, information is specifically routed along paths, and a query can fail whenever it reaches an adversarial node on its path.
- Also do not provide a Sybil resistance mechanism
- Privacy of which participant stores or requests what piece of information (from the curious eyes of other participants) is not guaranteed
With this in mind, we can return to the central questions on how to implement the bulletin-board and the read/write operations on it. Where are the coded chunks stored? How do they get there? Three prominent approaches under consideration are:
- GOSSIP: Disperse coded chunks using a gossip network. For instance, there could be a topic per coded chunk, and nodes in charge of storing a certain chunk could subscribe to the respective topic.
- DHT: Upload coded chunks into a DHT. The DHT would then “automatically” assign to each participant the chunks they should store.
- REPLICATE: Sample from nearby replicas. Some nodes store a full (or partial) replica of the data, and serve chunk requests to sampling nodes.
Challenges with these approaches are:
- How to ensure that “there is enough space on the bulletin board” to begin with (i.e., enough participants are subscribed to each topic in GOSSIP, or each node can store all chunks it is required to store under DHT), and that all parts of the bulletin board remain online as nodes churn over time? (Ideally, to ensure scalability, we would even want that storage is used efficiently, i.e., there should not be too much redundancy among what honest nodes store.) This would be particularly tricky in a truly permissionless system where nodes come and go, and where perhaps there is no Sybil resistance mechanism, so that a large majority of nodes could be adversarial and could disappear in an instant. Luckily, in the blockchain context, some Sybil resistance mechanism (such as PoS) is usually present and could be used to establish reputation or even slashing, but many details remain to be determined on how to leverage the Sybil resistance mechanism to secure the peer-to-peer network layer.
- Expanding on the preceding point, since networking underlies consensus and is thus the bedrock of what is supposed to be a Byzantine fault tolerant (BFT) system, the networking layer itself better be BFT—but as seen earlier, that is not the case for popular gossip or DHT protocols such as GossipSub or Kademlia. (Even REPLICATE might face this challenge, as a DHT may still be used in other parts of the network stack, e.g., for peer discovery; but at this point challenges with DHT become a general network-layer concern, not specific to data availability sampling.)
- Finally, some think that in the long run, nodes are supposed to store or forward no more than a quite small fraction of a block, otherwise scalability and the possibility to support relatively “weak” participants (cf. decentralization) is limited. This is antithetical to REPLICATE. For GOSSIP, this necessitates a large number of broadcast groups (“topics”) each with a small number of subscribers, a regime in which gossip protocols tend to become less reliable. In any case, the above approaches come with overhead, e.g., in bandwidth for forwarding chunks on behalf of other nodes, that must not exceed an individual node’s budget.
Challenge D: “How” do we implement the random sampling? This question is two-fold: how are the desired chunks located and transmitted in the network (i.e., how to “read” from the bulletin board), and how is it ensured that the sampling “remains random” with respect to the adversary, i.e., that an adversarial block producer does not have (too much) opportunity to change its strategy adaptively depending on who queries which chunks.
- Certainly, sampling directly from the block producer is not a viable option, due to the high bandwidth this would require from the block producer, and the associated denial-of-service vector if the block producer’s network address was known to everyone. (Some hybrid constructions that involve pulling from the block producer can be viewed through the lense of DHT and REPLICATE.)
- An alternative is to sample from “the swarm” after dispersing the chunks using one of the aforementioned methods (GOSSIP or DHT). Specifically:
- After the chunks have been dispersed using either GOSSIP or DHT, a DHT might come handy to route sampling requests and randomly sampled chunks—but this comes with the challenges discussed above, most notably lack of BFT and privacy.
- Alternatively, under GOSSIP, each node could subscribe to the topics corresponding to chunks it wants to sample—but with the challenges discussed above: besides lack of BFT and privacy, having a large number of topics with few subscribers each leads to unreliable communication.
- A compromise between “sample from the block producer” and “sample from the swarm” is possible with REPLICATE, where chunks are sampled from full replicas of the data, and replicas are identified among network peers.
Note that the above solve only sampling (“reading” from the bulletin board now), but not “reading” from the bulletin board at any time in the future. Specifically, GOSSIP essentially implements an ephemeral bulletin board (which can be read/sampled only at the time when its content is being written/dispersed), while DHT implements a permanent bulletin board (which can be read/sampled also much later). Typically, a permanent bulletin board is desired (with a permanence requirement ranging from “days” to “forever”, depending on the exact design), for which purpose GOSSIP has to be complemented with a DHT to route chunks, which comes with the aforementioned challenges. REPLICATE implements a permanent bulletin board right away.
The following table illustrates which peer-to-peer protocols are commonly proposed to realize which functionality of the model. Specifically, the gossip-oriented approach comes in two variants, one that uses gossip to sample chunks and one that uses a DHT to sample chunks, while in both “chunks are written on the bulletin board” using gossip and “read from it” at later points in time using a DHT. In contrast, the DHT-oriented approach relies entirely on a DHT for all the operations in question. In the replication-oriented approach, each node reads/samples chunks from a full replica nearby, using a request/response protocol. It effectively uses gossip for the initial dissemination of the chunks, albeit the gossipping between two peers might technically be realized through the request/response protocol.
| Approach | “Write” chunks | Sample chunks (while being written) | “Read” chunks (considerably later) |
| Gossip-oriented | Gossip | Gossip | DHT |
| DHT | |||
| DHT-oriented | DHT | ||
| Replication-oriented | Gossip | Request/response | Request/response |
Furthermore, in all above techniques, “who samples what” is leaked (at least partially) to the adversary, so that the adversary can, through its own behavior, adaptively impair/promote the propagation of chunks sampled by certain nodes, and thus trick certain nodes into believing that the block is (un-)available. While the earlier work shows that only few nodes can be tricked, this is undesirable. Alternatively, earlier works assume anonymous network communication, which in practice at least comes with a considerable performance penalty, if not outright impractical.
Challenge E: How to “repair” the board’s content? That is, if a coded chunk goes missing (for example because nodes storing that chunk have gone offline; how is that even detected?), how is it recovered? Naive repair involves decoding and re-encoding, and thus poses a considerable communication and computational burden, in particular for the common Reed-Solomon erasure-correcting codes. Who takes on this burden? How are they compensated? How is it avoided that a malicious block producer can grief sampling nodes by withholding a few coded chunks and forcing nodes to spend resources on expensive repair? What about distributed repair schemes? How are the chunks that are necessary for repair even retrieved, going back to the previous point about “reading” from the board in the future.
Challenge F: Incentives. If sampling is free, how to prevent a denial-of-service vector? If sampling requires payment (how to implement?), how can it simultaneously be fully anonymous? How are those compensated that store (parts of) the bulletin board, route information in the peer-to-peer network, or perform maintenance tasks such as chunk repair?
The Other Model
For completeness, we briefly mention a slightly different model for which DAS achieves a slightly different guarantee. Even without anonymous and reliable networking, an adversary can trick at most a certain number of honest nodes into believing that an unavailable file is available. Otherwise, it would have to release so many chunks that from the union of all chunks obtained by honest nodes the file can be recovered. The advantage of this model is that the properties required from the network are easier to achieve (in particular, when the peer-to-peer network has been subverted by the adversary). Disadvantages are that there is no concrete guarantee for an individual user (you could be among the few tricked!), and that it remains unclear how to gather all the samples obtained by honest nodes and recover the file (in particular, when the peer-to-peer network has been subverted by the adversary).
Future Research & Development Directions
Based on the observations and arguments presented in this blog post, we think the following will be some interesting directions for future research and development:
- It seems clear that some Sybil resistance mechanism is necessary to secure the network layer (right now, arguably, network protocols often implicitly depend on the scarcity of IP addresses for this purpose, see for instance GossipSub v1.1’s peer scoring). Conveniently, the consensus layer provides exactly that, e.g., in the form of proof-of-stake. It thus seems natural to reuse the consensus layer’s Sybil resistance mechanism on the network layer, for instance to sample one’s peers in a gossip protocol from the validator set (and thus “inherit” the power of the consensus’ honest majority assumption). While this might not immediately secure the networking of nodes that aren’t also active consensus participants, it can help build a secure “backbone” among consensus nodes (and thus strengthen consensus security), and subsequently perhaps be a stepping stone to enable better security for everyone. A logical next step on this path would be the careful analysis of the interplay of consensus and networking with such a shared Sybil resistance mechanism (this is a recent first step in that direction).
- Improved gossip and DHT protocols: (cf. this survey)
- Byzantine fault tolerance (BFT), in particular using Sybil resistance mechanisms commonly found on the consensus layer
- Efficiency (in particular for BFT variants, which so far come with considerable overhead and/or low adversarial resilience)
- Privacy guarantees (improved guarantees, and better efficiency/lower overhead)
- Repair mechanisms:
- Implementing repair in a distributed way (erasure-correcting codes with locality?)
- Studying and designing the relevant incentives
If you are working on (or interested to work on) any of these directions, I would love to hear from you! You can reach me on Twitter at @jneu_net.
Acknowledgments: Special thanks to Mustafa Al-Bassam, Danny Ryan, Dankrad Feist, Sreeram Kannan, Srivatsan Sridhar, Lei Yang, Dan Robinson, Georgios Konstantopoulos, and Dan Lee for fruitful discussions and feedback on earlier drafts of this post, and to Achal Srinivasan for the beautiful illustrations.
Disclaimer: This post is for general information purposes only. It does not constitute investment advice or a recommendation or solicitation to buy or sell any investment and should not be used in the evaluation of the merits of making any investment decision. It should not be relied upon for accounting, legal or tax advice or investment recommendations. This post reflects the current opinions of the authors and is not made on behalf of Paradigm or its affiliates and does not necessarily reflect the opinions of Paradigm, its affiliates or individuals associated with Paradigm. The opinions reflected herein are subject to change without being updated. Paradigm invests in certain of the protocols referenced herein. These references are not meant to endorse or recommend these protocols for investment or otherwise.