Reth’s path to 1 gigagas per second, and beyond
Apr 24, 2024 | Georgios Konstantopoulos
Contents

We started building Reth in 2022 to provide resilience to Ethereum L1, and solve execution layer scaling on Layer 2.
Today we’re excited to share Reth’s path towards 1 gigagas per second in L2 in 2024, and our longer-term roadmap for going beyond that.
We invite the ecosystem to collaborate with us as we push the frontier of performance and rigorous benchmarking in crypto.
Are we scaled yet?
There’s a very simple path for cryptocurrencies to reach global scale and escape speculation as the dominant use case: Transactions need to be cheap and fast.
How do you measure performance? What does gas per second mean?
Performance is typically measured by the metric "Transactions Per Second" (TPS). Particularly for Ethereum and other EVM blockchains, a more nuanced and perhaps accurate measure is "gas per second." This metric reflects the amount of computational work that the network can handle every second, where "gas" is a unit that measures the computational effort required to execute operations like transactions or smart contracts.
Standardizing around gas per second as a performance metric allows for a clearer understanding of a blockchain's capacity and efficiency. It also helps in assessing the cost implications on the system, safeguarding against potential Denial of Service (DOS) attacks that could exploit less nuanced measurements. This metric helps compare the performance across different Ethereum Virtual Machine (EVM) compatible chains.
We propose to the EVM community to adopt gas per second as a standard metric, alongside incorporating other dimensions of gas pricing to create a comprehensive performance standard.
Where are we today?
Gas per second is determined by dividing the target gas usage per block by the block time. Here, we showcase the current gas per second throughput and latency across various EVM chains L1s and L2s (not exhaustive):
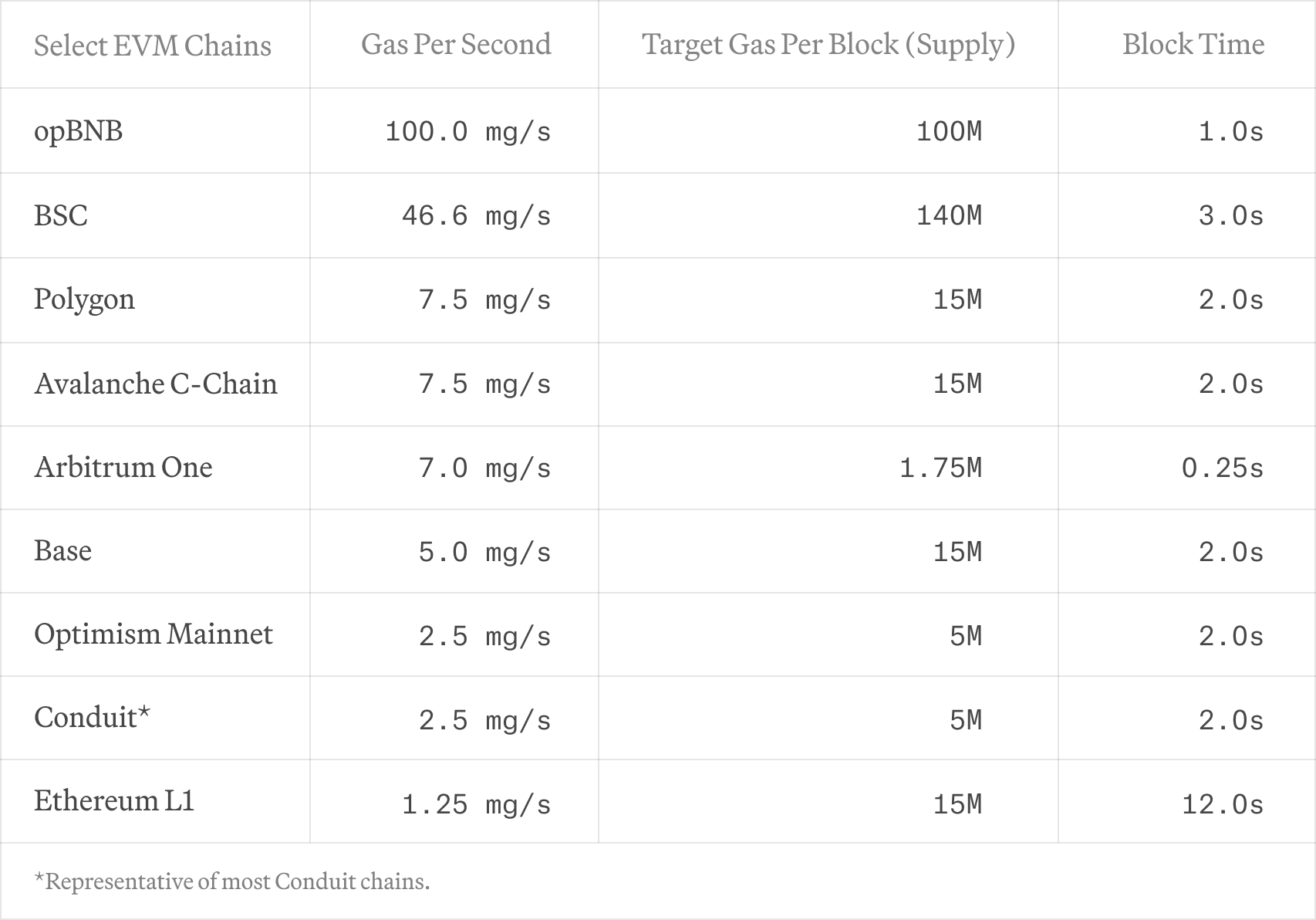
We emphasize gas per second to thoroughly assess EVM network performance, capturing both compute and storage costs. Networks like Solana, Sui, or Aptos are not included due to their distinct cost models. We encourage efforts towards harmonizing cost models across all blockchain networks to enable comprehensive and fair comparisons.
We are working on a continuous benchmarking suite for Reth replicating real workload, if you want to collaborate on this, please reach out. We need a TPC Benchmark for nodes.
How will Reth get to 1 gigagas per second? Beyond that?
We were partially motivated to build Reth in 2022 by the pressing need to have a client purpose-built for web-scale rollups. We think we have a promising path forward.
Reth already achieves 100-200mgas/s during live sync (including senders recovery, executing transactions, and calculating the trie on every block); 10x from here gets us to the our short-term goal of 1 gigagas/s.
As we advance Reth's development, our scaling plan has to balance scalability with efficiency:
- Vertical Scaling: Our goal here is to maximize the use of each "box" to its full potential. By optimizing how each individual system handles transactions and data, we can greatly enhance the overall performance, while also making it more efficient for individual node operators.
- Horizontal Scaling: Despite the optimizations, the sheer volume of transactions at web scale exceeds what any single server can handle. To address this, we want to implement a horizontally scaled architecture, similar to a Kubernetes model for blockchain nodes. This means spreading the workload across multiple systems to ensure that no single node becomes a bottleneck.
The optimizations we are exploring here do not involve solving state growth, which we are researching separately.
Here’s a summary of how we intend to get there:
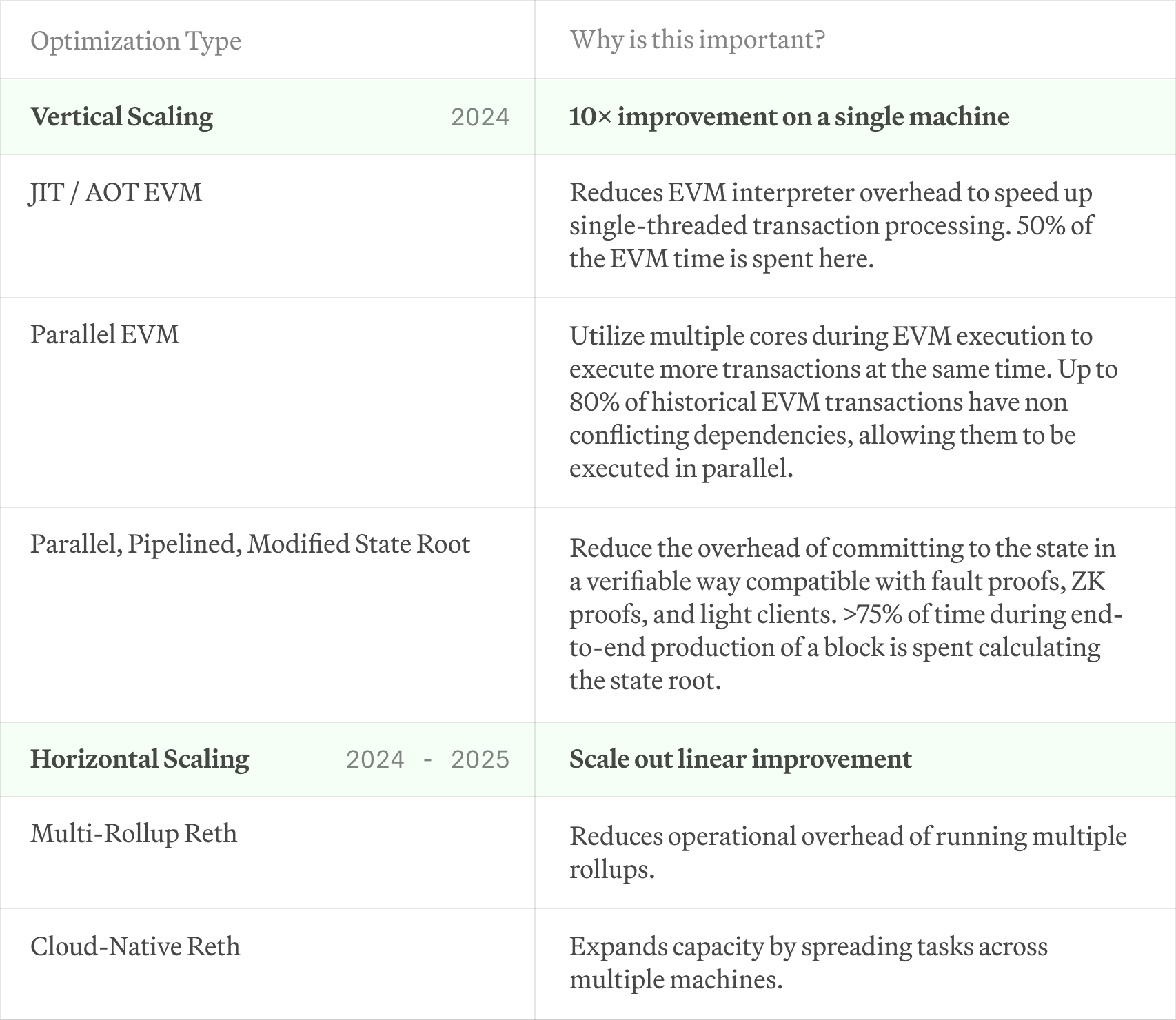
Across the entire stack we are also optimizing for IO and CPU using the actor model, to allow each part of the stack to be deployed as a service with fine control over its utilization. Finally, we are actively evaluating alternative databases, but have not decided yet on a candidate.
Reth’s vertical scaling roadmap
Our goal here is to maximize the performance and efficiency of a single server or laptop running Reth.
Just-In-Time & Ahead-of-Time EVM
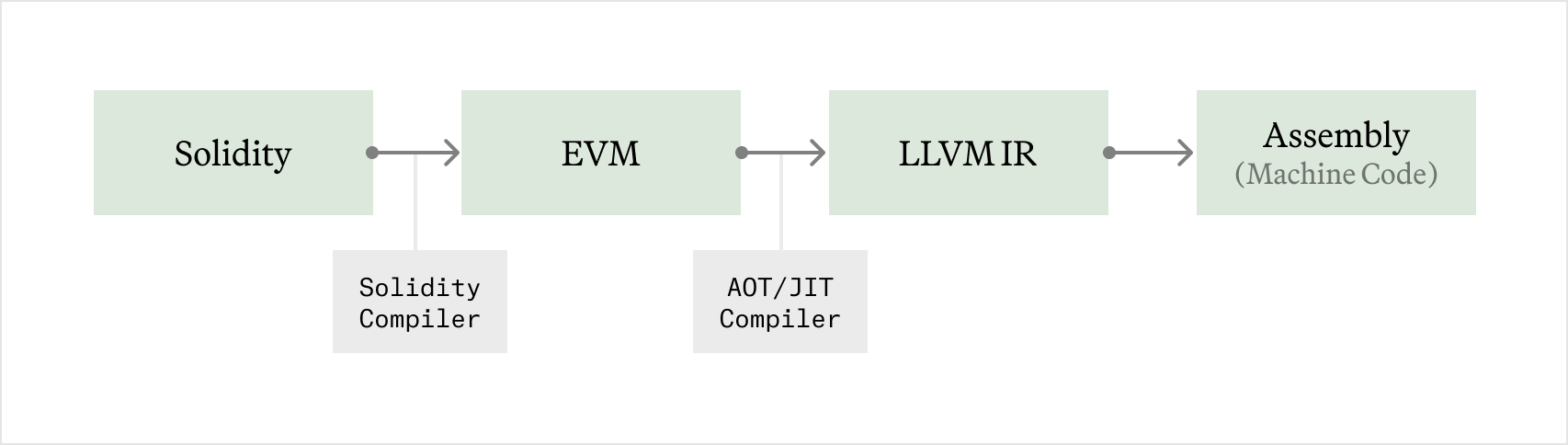
In blockchain environments like the Ethereum Virtual Machine (EVM), bytecode execution happens through an interpreter, which sequentially processes instructions. This method introduces overhead because it doesn't execute native assembly instructions directly, instead operating through the VM layer.
Just-In-Time (JIT) compilation addresses this by converting bytecode to native machine code just before execution, thereby improving performance by bypassing the VM's interpretative process. This technique, which compiles contracts into optimized machine code ahead of time, is well-established in other VMs like Java and WebAssembly.
However, JIT can be vulnerable to malicious code designed to exploit the JIT process, or may be too slow to run live during execution. Reth will Ahead-of-Time (AOT) compile the highest demand contracts and store them on disk, to avoid untrusted bytecode trying to abuse our native-code compilation step during live execution.
We have been working on a JIT/AOT compiler for Revm, currently being integrated with Reth. We will open source this in the coming weeks once our benchmarking is done. About 50% of execution time is spent in the EVM interpreter on average, so this should provide a ~2x EVM execution improvement, although in some more compute heavy cases it might be even more impactful. We will be sharing our benchmarks and integration of our own JIT EVM in Reth in the coming weeks.
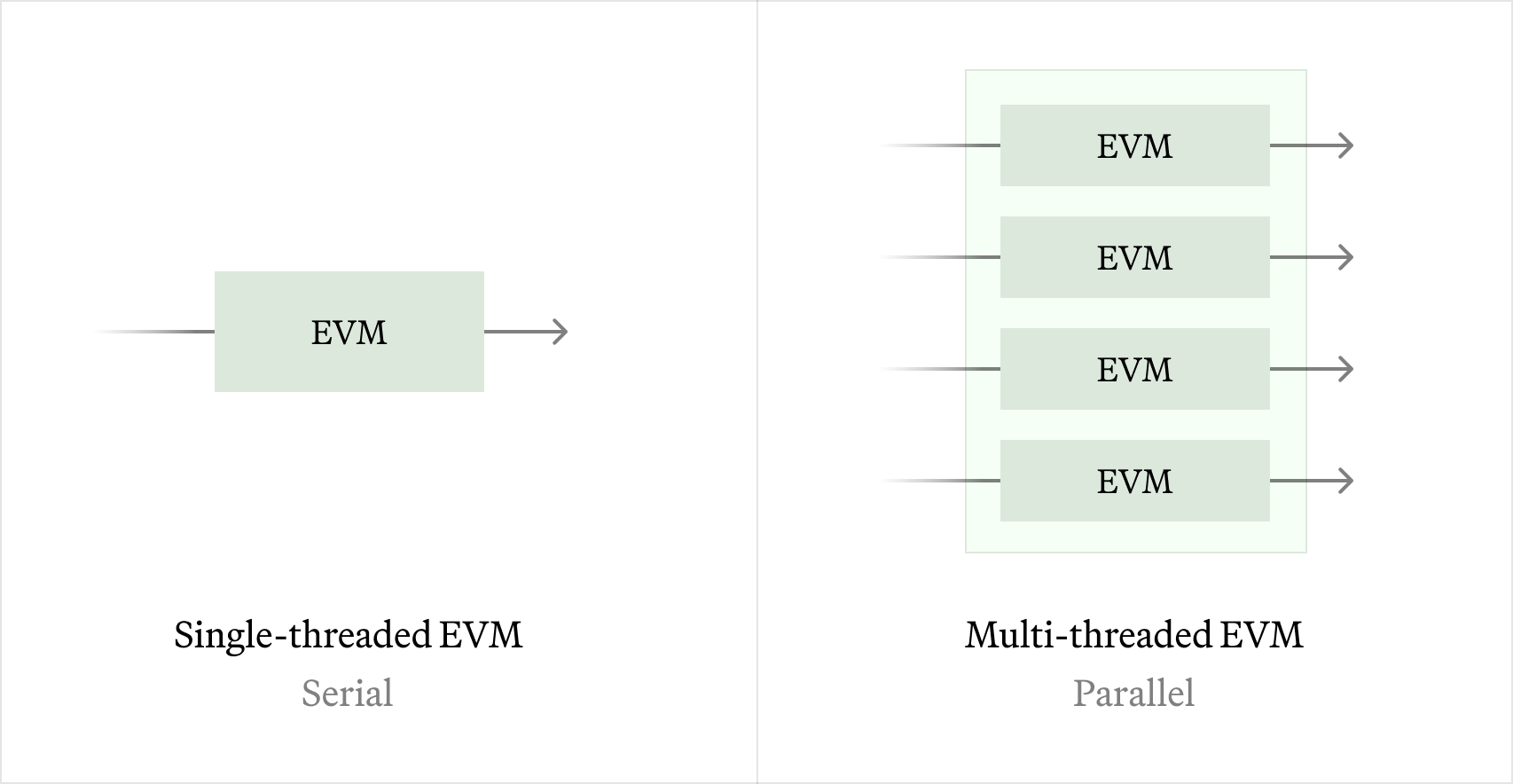
Parallel EVM
The concept of a Parallel Ethereum Virtual Machine (Parallel EVM) enables simultaneous transaction processing, diverging from the traditional serial execution model of the EVM. We have 2 paths forward here:
- Historical Sync: In historical synchronization, we can calculate the best possible parallelization schedule by analyzing past transactions and identifying all historical state conflicts. See our early attempt at this in an old branch on Github.
- Live Sync: For live synchronization, we can use Block STM-like techniques to speculatively execute without any additional information like access lists. This algorithm has poor performance during periods of heavy state contention, so we want to explore switching between serial and parallel execution depending on the shape of the workload, as well as statically predicting which storage slots will be accessed to improve the quality of the parallelism. See one PoC by a 3rd party team here.
Based on our historical analysis, ~80% of Ethereum storage slots are accessed independently, meaning parallelism could yield up to 5x improvement in EVM execution.
Improving the State Commitment
We recently wrote about the impact of state root in performance and the differences between the Reth database model from other clients, as well as why it is important.
In the Reth model, calculating the state root is a separate process from executing transactions (see our code), enabling the usage of standard KV stores that do not need to know anything about the trie. This currently takes >75% of the end to end time to seal a block, and is a very exciting area to optimize.
We identify the following 2 “easy wins” which can give us 2-3x in the state root performance, without any protocol changes:
- Fully Parallelized State Root: Right now we only re-calculate the storage trie for changed accounts in parallel, but we can go further and also calculate the accounts trie in parallel while the storage root jobs complete in the background.
- Pipelined State Root: Pre-fetch intermediate trie nodes from the disk during execution by notifying the state root service about storage slots and accounts touched.
Going beyond that, we see a few paths forward by diverging from Ethereum L1 state root behavior:
- Less frequent State Root: Instead of calculating the state root on every block, calculate it every T blocks. This reduces the overall % of the time spent in the state root in the entire system and could be the easiest and most effective solution.
- Trailing State Root: Instead of having to calculate the state root at the same block, let it lag behind a few blocks. This allows execution to advance without blocking on the state root calculation.
- Replace the RLP Encoder & Keccak256: Instead of encoding with RLP, it may be cheaper to just concatenate the bytes and use a faster hash function like Blake3.
- Wider Trie: Increase the N-arity of the tree, to reduce the IO amplification due to the logN depth of the trie.
There are a few questions here:
- What are the second order effects of the above changes on light clients, L2s, bridges, coprocessors and other protocols that rely on frequent account & storage proofs?
- Can we both optimize the state commitment for SNARK proving and for native execution speed?
- What is the widest state commitment that we can get with the tools we have available to us? What second order effects are there around the witness size?
Reth’s horizontal scaling roadmap
We will execute on multiple of the above points throughout 2024 and achieve our goal of 1gigagas/sec.
However, vertical scaling ultimately encounters physical and practical limits. No single machine can handle the world's computing needs. We think there are 2 paths forward here, which allow us to scale out by introducing more boxes as more load arrives:
Multi-Rollup Reth
Today’s L2 stacks require running multiple services to follow the chain: L1 CL, L1 EL, the L1 -> L2 derivation function (which may be bundled with the L2 EL), and the L2 EL. While great for modularity, this gets complicated when running multiple node stacks. Imagine having to run 100 rollups!
We want to allow launching rollups in the same process as Reth and drive the operating cost of running thousands of rollups to almost zero.
We are already underway with this with our Execution Extensions projects ([1], [2]), more in the coming weeks here.
Cloud-native Reth
High performance sequencers may have enough demand on a single chain that they need to scale out to beyond a single machine. This is not possible in today’s monolithic node implementations.
We want to allow running Cloud-native Reth nodes, deployed as a service stack that can autoscale with compute demand and use the seemingly infinite cloud object storage for persistence. This is a common architecture in serverless database projects such as NeonDB, CockroachDB or Amazon Aurora.
See early thoughts from our team on some ways we could go about this problem.
Outlook
We intend to roll out this roadmap incrementally to all Reth users. Our mission is to give everyone access to 1 gigagas/s and beyond. We will be testing our optimizations out on Reth AlphaNet, and we hope people will build modified high performance nodes using Reth as an SDK.
There are some questions we have not arrived at answers for yet.
- How can Reth help with improving performance across the L2 ecosystem?
- How do we appropriately measure worst case scenarios when some of our optimizations might be for the average case?
- How do we manage the tension between L1 and L2 potentially diverging?
We do not have answers to many of these questions, but we have enough initial promising leads to keep us busy for a while and hope to see these efforts bear fruit in the coming months.
We will move the needle on scaling Ethereum. If you’re excited about contributing to breaking the 1gigagas/s barrier for EVM Rollups, reach out to georgios@paradigm.xyz.
Georgios Konstantopoulos is the Chief Technology Officer and a General Partner focused on Paradigm’s portfolio companies and research into open-source protocols. Previously, Georgios was an independent consultant and researcher focused [→]
Disclaimer: This post is for general information purposes only. It does not constitute investment advice or a recommendation or solicitation to buy or sell any investment and should not be used in the evaluation of the merits of making any investment decision. It should not be relied upon for accounting, legal or tax advice or investment recommendations. This post reflects the current opinions of the authors and is not made on behalf of Paradigm or its affiliates and does not necessarily reflect the opinions of Paradigm, its affiliates or individuals associated with Paradigm. The opinions reflected herein are subject to change without being updated.